| 深度之眼Paper带读笔记NLP.21:QANet | 您所在的位置:网站首页 › paper withcode › 深度之眼Paper带读笔记NLP.21:QANet |
深度之眼Paper带读笔记NLP.21:QANet
|
文章目录
前言第一课 论文导读机器阅读理解任务介绍机器阅读理解研究意义机器阅读理解的范式片段抽取式机器阅读理解答案选择机器阅读理解完形填空式机器阅读理解文本生成机器阅读理解
机器阅读理解评价指标
机器阅读理解相关技术机器阅读理解模型框架编码器循环神经网络vs卷积神经网网络注意力机制
前期知识储备
第二课 论文精读论文整体框架传统算法模型详解基于双向注意力流的模型双向注意力流层
论文提出的模型论文动机模型结构
实验和结果讨论和总结
前言
QANet:Combining Local Convolution with Global Self-Attention for Reading Comprehension QANet:在阅读理解中使用局部卷积和全局自注意力 作者:Wei Yu、David Dohan、Minh-Thang Luong 单位:Carnegie Mellon University & Google Brain 发表会议及时间:ICLR 2018(表示学习的顶会) 在线LaTeX公式编辑器 了解记忆网络的概念,了解RNN序列模型以及它的两种变体GRU和LSTM。 机器阅读理解的定义 机器阅读理解,是指让机器像人类一样阅读文本,进而根据对该文本的理解来回答问题。直观来讲,这种阅读理解就像是让计算机来做我们高考英语的阅读理解题。让机器完成阅读理解与问答是当前AI界前沿的一个火热主题,被视为是自动问答(Question Answering, QA)中的一个重要问题,主要涉及到深度学习、自然语言处理和信息检索等相关技术。 机器阅读理解的四种形式 片段抽取式机器阅读理解 答案选择机器阅读理解 完形填空式机器阅读理解 文本生成机器阅读理解 机器阅读理解框架结构 首先,输入篇章与问题的文本,经过表示层将文本转换为语义向量表示;然后,在编码层中,使用编码器对语义向量表示进行建模编码,使得模型能获得更高层次的表示;之后,在匹配层中,引入注意力机制。由于机器阅读理解任务中,问题与篇章并非相互孤立的存在,对两者进行交互联系,可以让模型更有效地聚焦于较重要的部分;最后,在答案层使用编码器继续编码当前的蕴含了相互信息的表示,并使用softmax来获得答案片段的开始与结束位置的概率分布。 第一课 论文导读 机器阅读理解任务介绍机器阅读理解,是指让机器像人类一样阅读文本,进而根据对该文本的理解来回答问题。直观来讲,这种阅读理解就像是让计算机来做我们高考英语的阅读理解题。 让机器完成阅读理解与问答是当前Al界前沿的一个火热主题,被视为是自动问答(Question Answering,QA)中的一个重要问题,主要涉及到深度学习、自然语言处理和信息检索等相关技术。 下图是IBM做的一个东西,在一个知识问答竞赛上击败人类。
片段抽取式机器阅读理解 答案选择机器阅读理解 完形填空式机器阅读理解 文本生成机器阅读理解 片段抽取式机器阅读理解该类型的机器阅读理解任务需要预测的答案大多是一个篇章中存在的词语或者连续片段,或者可以认为需要从篇章中抽取一个连续片段作为答案。基于此特性,片段抽取式机器阅读理解可以被转化为预测答案片段的开始结束两个位置
p
s
p_s
ps和
p
e
p_e
pe的任务,其中
1
≤
p
s
≤
p
e
≤
n
1≤p_s≤p_e≤n
1≤ps≤pe≤n,因此,答案可使用篇章中的词片段表示为
[
p
s
,
p
e
]
[p_s,p_e]
[ps,pe]。 代表性数据集:SQuAD 在给定问题
Q
Q
Q与篇章
P
P
P后,给出两个或多个预设答案
A
=
a
1
,
a
2
…
a
n
A={a_1,a_2…a_n}
A=a1,a2…an供选择,此处
a
1
a_1
a1可以是单词,也可以是句子。该任务在答案选择步骤也可以看作是一个排序任务,需要根据篇章与问题,从中排序选择最合适的答案。(和英语的阅读理解最类似) 对于这一类方法,也有给出篇章
P
P
P和答案集
A
A
A,从中选择语境相符或者预测下一句的细分任务,而这一任务通常也被当做是自然语言推理任务(NLI)。 代表性数据集:MCTest 同样在给定问题Q与篇章P,而篇章P的某些位置存在缺失的词语,用占位符进行标识。任务需要根据占位符的上下文信息,推理出可以合理填入的答案词。答案词通常为单个词语,且答案词的类型根据数据集有多种,如预测固定搭配的介词或根据描述的事实来填入命名实体。 同时,答案词通常是包含于词典V,或是以预设几个答案供以选择回答。后者亦可视为答案为词级别的答案选择式机器阅读理解任务。 代表性数据集:CNN/Daily Mail 不同于以上的几种形式,这种基于生成式的阅读理解的答案不局限于原始篇章中存在的词语,而是可以根据问题与篇章自由生成相应的答案词语或答案句子。 代表性数据集:NarrativeQA 片段抽取式,实验结果会同时提供两个评估指标以供具体的分析, 1.完全匹配值(Exact Match,EM),该指标判定时,严格要求预测的答案片段需要与正确答案片段完全一致,假设预测结果为 [ p s p , p e p ] [p_s^p,p_e^p] [psp,pep],标记结果为 [ p s g , p e g ] [p_s^g,p_e^g] [psg,peg]: 下式中表示score只有预测的开始与结果的开始相同,预测的结束语结果的结束相同的时候才为1(完全匹配),否则为0。 E M s c o r e = { 1 , i f p s p = p s g a n d p e p = p e g 0 , o t h e r w i s e EM\space score=\left\{\begin{matrix} 1,\space if\space p_s^p=p_s^g\space and\space p_e^p=p_e^g\\ 0,\space otherwise \end{matrix}\right. EM score={1, if psp=psg and pep=peg0, otherwise 2.F1值,不同于EM值的完全匹配,F1值的方式评判预测的答案片段与正确答案的重合率,根据重合数与正确标注的字符数计算召回率,重合数与预测出的所有字符数计算准确率: F 1 s c o r e = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1\space score=\frac{2×Precision×Recall}{Precision+Recall} F1 score=Precision+Recall2×Precision×Recall 此外,答案选择式、完形填空式使用Accuracy,文本生成式使用BLEU、ROUGE等。 机器阅读理解相关技术 机器阅读理解模型框架首先,输入篇章与问题的文本,经过表示层将文本转换为语义向量表示; 然后,在编码层中,使用编码器对语义向量表示进行建模编码,使得模型能获得更高层次的表示; 之后,在匹配层中,引入注意力机制。由于机器阅读理解任务中,问题与篇章并非相互孤立的存在,对两者进行交互联系,可以让模型更有效地聚焦于较重要的部分; 最后,在答案层使用编码器继续编码当前的蕴含了相互信息的表示,并使用softmax来获得答案片段的开始与结束位置的概率分布。 QA-LSTM模型使用Bi-LSTM对问题句和候选答案句独立处理分别生成其分布式表示,然后经过池化操作得到对句子的向量表示,最后使用余弦相似度衡量二者的距离。 为了能够进一步捕获更多的特征,Bi-LSTM上面可以再加一层卷积神经网络,这样得到的结果不仅含有了上下文感知的能力,还能够捕获一些结构化信息。 循环神经网络 优点:NLP的输入往往是个不定长的线性序列句子,而RNN可以接纳不定长的输入,由前向后进行信息传导,并且LSTM在引入三个门后,对于捕获长距离特征也是非常有效的。 缺点:RNN本身的序列依赖结构对于大规模并行计算来说比较困难,只能按照时间步一个单词一个单词往后走,很难具备高效的并行计算能力。 卷积神经网络 优点:对于某个卷积核来说,每个滑动窗口位置之间没有依赖关系,另外,不同的卷积核之间也没有相互影响,所以完全可以并行计算。 缺点:单层卷积神经网络捕获特征的距离长度取决于卷积核的宽度,无法捕获长距离依赖关系。并且,池化层会破坏词之间的相对位置信息。 注意力机制注意力机制最初用于解决序列到序列模型中对信息高度压缩后可能产生的信息丢失问题,之后不断应用到其他自然语言处理任务当中。计算注意力通常分为以下三步:对于每个位置的
h
i
h_i
hi以及对
h
i
h_i
hi产生影响的查询向量
u
i
ui
ui,首先,计算
h
i
h_i
hi和
u
i
u_i
ui的相似度,然后,对相似度进行归一化得到注意力权重
a
i
a_i
ai。最后,将权重而赋权给相应的
h
i
h_i
hi并进行加权求和:
s
i
=
g
(
h
i
,
u
i
,
θ
g
)
s_i=g(h_i,u_i,\theta_g)
si=g(hi,ui,θg)
a
i
=
e
x
p
(
s
i
)
∑
j
=
1
n
e
x
p
(
s
j
)
a_i=\frac{exp(s_i)}{\sum_{j=1}^nexp(s_j)}
ai=∑j=1nexp(sj)exp(si)
c
=
∑
i
=
1
n
a
i
h
i
c=\sum_{i=1}^na_ih_i
c=i=1∑naihi 直观来说,注意力机制为每个位置计算一个相似度分数。因此,a能有效地捕获句子中真正相关的部分,最终的输出c以加权求和的方式来结合所有时间步的信息并用于后续的预测。其中
g
(
⋅
)
g(·)
g(⋅)是一个可以具体选择的匹配对齐函数,对注意力机制的设计也就体现在这个函数上。 机器阅读理解:了解机器阅读理解的概念,掌握机器阅读理解的主要研究方向和评价指标。 MRC相关技术:掌握机器阅读理解模型的基本框架结构及其相关技术,掌握其优缺点。 卷积神经网络:掌握卷积神经网络(CNN)的基本原理与其在自然语言处理中的应用。 自注意力机制:了解自注意力机制的核心思想和主要作用,掌握自注意力机制的实现形式。 第二课 论文精读 论文整体框架0.摘要 1.引言 2&3.模型&数据增强 4.实验 5.相关工作 6.结论 传统算法模型详解介绍在论文改进前的原有模式模型 基于双向注意力流的模型Bidirectional Attention Flow for Machine Comprehension BiDAF模型包括6层: 1.字嵌入层:用字符级CNNs将每个字符映射到向量空间。 2.词嵌入层:利用预训练的词嵌入模型,将每个词映射到向量空间,使用高速路网络来拼接字嵌入和词嵌入。 3.上下文嵌入层:利用周围单词的上下文线索(RNN)来细化单词的嵌入,这前三层同时应用于问句和篇章。 4.双向注意力流层:将问句向量和篇章向量进行耦合,并为文章中每个词生成一个问句相关的特征向量集合。 5.建模层:再次使用Bi-LSTM扫描整个篇章,捕获包含问句特征的篇章单词之间的上下文依赖关系。 6.输出层:输出问句对应的回答,也就是说,标出开始位置和结束位置。 Query2Context:度量对问句中的每一个单词而言,篇章中的哪些单词与其最相关。根据相关性矩阵,对每列取最大值,最后进行softmax归一化计算篇章中所有单词的加权和,得到一个维度为d的向量后,重复T次得到一个dxT的矩阵
H
~
\tilde H
H~。 Context2Query:度量对篇章中的每一个单词而言,问句中的哪些单词与其最相关。根据相关性矩阵,使用softmax对列归一化然后逐一计算问句中所有单词的加权和,得到一个dxT的矩阵
U
~
\tilde U
U~。
G
:
t
=
β
(
H
:
t
,
U
~
:
t
,
H
~
:
t
)
∈
R
d
G
G_{:t}=\beta(H_{:t},\tilde U_{:t},\tilde H_{:t})\in\R^{d_G}
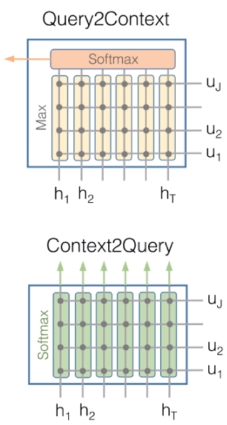
G:t=β(H:t,U~:t,H~:t)∈RdG 优点:没有使用注意力机制把上下文编码进固定长度的向量,而是让其随着单词信息流动,从而减少过早加权求和带来的信息损失。 已有方法的有效性主要依赖于两个点:RNN和Attention 循环神经网络善于引入长距离推理,但是因为其运算方式,速度较慢;卷积神经网络距离特征捕捉能力较弱,且池化层会加大位置信息的损失,但是因为对并行操作的友好,其计算速度是循环神经网络无法比拟的,因此增加了可操作空间,并更适合与实际落地应用。 除此之外,自注意力机制可以和CNN一样不依赖于前一时刻的计算,实现很好的并行,同时,在长距离依赖上,自注意力是每个词和所有词都要计算相似度,所以不管他们中间有多长距离,在计算时都是同等对待的,可以高效捕获长距离依赖关系。 和现有的阅读理解模型相类似,QANet包含五个主要的组成部分:输入层,嵌入编码层(包括字嵌入和词嵌入),篇章-问句注意力层,模型编码层以及输出层。 和BiDAF不同,QANet主要将编码层与答案抽取层中的LSTM结构模块换为CNN结构模块,并在编码器中加入自注意力机制来克服CNN不能捕获长距离依赖关系的缺点。 在机器阅读理解这类对长距离信息具有依赖的任务中,使用CNN作为编码器会丢失较多信息。因此,在编码器模块中,需要加入一些辅助的模块来完善模型这方面的短板。 编码层(位置编码)首先,考虑到使用CNN结构来进行编码,为了不丢失其位置信息,在进行编码之前,先使用工作[Attention is all you need]中的位置编码的方式直接引入绝对位置,来模拟词语的顺序: P E p o s , 2 i = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{pos,2i}=sin(pos/10000^{2i/d_{model}}) PEpos,2i=sin(pos/100002i/dmodel) P E p o s , 2 i + 1 = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{pos,2i+1}=cos(pos/10000^{2i/d_{model}}) PEpos,2i+1=cos(pos/100002i/dmodel) 这里,pos表示当前位置,i表示位置向量的第i维, d m o d e l d_{model} dmodel是总维度。 编码层(深度可分离卷积) CNN部分使用深度可分离卷积结构,将传统的卷积结构分解为深度卷积和逐点卷积。前者每个卷积核只跟输入的每个通道进行卷积,后者则将上一层的卷积结果进行合并。使用这样的方法能够进一步缩短卷积的计算时间,并且具有较好的记忆能力与泛化能力。 |

 机器阅读理解无论是在工业界还是学术界都有着很高的研究价值,它能够让计算机帮助人类在大量文本中找到想要的答案,从而减轻人们对信息的获取成本。也许,未来的搜索引擎将不仅仅是返回用户相关的链接和网页,而是通过对互联网上的海量资源进行阅读理解,直接得出答案返回给用户。 现在的搜索引擎已经部分完成该功能
机器阅读理解无论是在工业界还是学术界都有着很高的研究价值,它能够让计算机帮助人类在大量文本中找到想要的答案,从而减轻人们对信息的获取成本。也许,未来的搜索引擎将不仅仅是返回用户相关的链接和网页,而是通过对互联网上的海量资源进行阅读理解,直接得出答案返回给用户。 现在的搜索引擎已经部分完成该功能





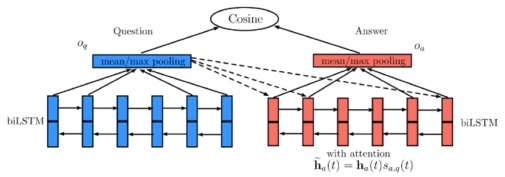 针对问题句的内容来生成候选答案句的向量表示 上面的h和u都在同一个句子,就形成了自注意力机制: 自注意力:其目的是为了能够关联同一输入序列的不同位置,把自己当做查询向量。在机器阅读理解任务中,将篇章中的每个词语与篇章中的其他词语进行对齐,希望能对篇章中的共指问题与信息聚合有帮助。具体来说,若有篇章词表示
P
=
p
1
,
p
2
.
…
,
p
n
P={p_1,p_2.…,p_n}
P=p1,p2.…,pn,对于每个向量
p
i
p_i
pi,将其与每一个词进行对齐:
a
i
j
=
e
x
p
(
s
(
p
i
,
p
j
)
)
∑
k
e
x
p
(
s
(
p
i
,
p
k
)
)
a_{ij}=\frac{exp(s(p_i,p_j))}{\sum_{k}exp(s(p_i,p_k))}
aij=∑kexp(s(pi,pk))exp(s(pi,pj))
c
i
=
∑
j
a
i
j
p
i
c_i=\sum_{j}a_{ij}p_i
ci=j∑aijpi 全局注意力:使用整个输入序列进行注意力加权计算 局部注意力:围绕当前词位置的窗口计算上下文向量
针对问题句的内容来生成候选答案句的向量表示 上面的h和u都在同一个句子,就形成了自注意力机制: 自注意力:其目的是为了能够关联同一输入序列的不同位置,把自己当做查询向量。在机器阅读理解任务中,将篇章中的每个词语与篇章中的其他词语进行对齐,希望能对篇章中的共指问题与信息聚合有帮助。具体来说,若有篇章词表示
P
=
p
1
,
p
2
.
…
,
p
n
P={p_1,p_2.…,p_n}
P=p1,p2.…,pn,对于每个向量
p
i
p_i
pi,将其与每一个词进行对齐:
a
i
j
=
e
x
p
(
s
(
p
i
,
p
j
)
)
∑
k
e
x
p
(
s
(
p
i
,
p
k
)
)
a_{ij}=\frac{exp(s(p_i,p_j))}{\sum_{k}exp(s(p_i,p_k))}
aij=∑kexp(s(pi,pk))exp(s(pi,pj))
c
i
=
∑
j
a
i
j
p
i
c_i=\sum_{j}a_{ij}p_i
ci=j∑aijpi 全局注意力:使用整个输入序列进行注意力加权计算 局部注意力:围绕当前词位置的窗口计算上下文向量

 输入层: 这里既采用了单词级别的向量(预训练的Glove)又用到了字符级别的向量。拼接后的向量通过两层的高速路网络来提升嵌入向量的表征能力同时缓解梯度回传的困难。 编码层: 每一个编码器首先使用了位置编码,随后包括一组CNN,一个自注意力层和一个前馈神经网络层。
输入层: 这里既采用了单词级别的向量(预训练的Glove)又用到了字符级别的向量。拼接后的向量通过两层的高速路网络来提升嵌入向量的表征能力同时缓解梯度回传的困难。 编码层: 每一个编码器首先使用了位置编码,随后包括一组CNN,一个自注意力层和一个前馈神经网络层。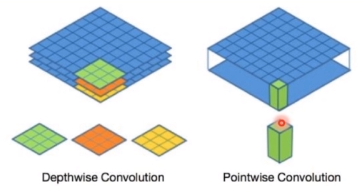 除此之外,文章还使用了残差结构:记输入为x,操作为f(这里为卷积)那么输出为
f
(
l
a
y
e
r
n
o
r
m
(
x
)
)
+
x
f(layernorm(x))+x
f(layernorm(x))+x,layernorm是层归一化。
除此之外,文章还使用了残差结构:记输入为x,操作为f(这里为卷积)那么输出为
f
(
l
a
y
e
r
n
o
r
m
(
x
)
)
+
x
f(layernorm(x))+x
f(layernorm(x))+x,layernorm是层归一化。 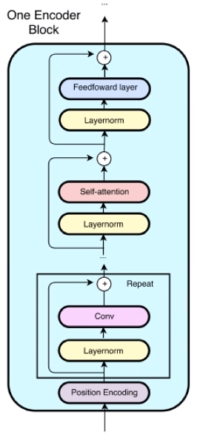 编码层(自注意力)直观来说,就是在计算单个词语的表示时,将其与输入语句所有的词语进行注意力权重计算,学习到句子内部的词语之间的依赖关系,从而来捕捉输入句子的内部结构与交互。 自注意力机制正式介绍出自《Attention is all you need》,是Transformer和BERT的核心结构。
编码层(自注意力)直观来说,就是在计算单个词语的表示时,将其与输入语句所有的词语进行注意力权重计算,学习到句子内部的词语之间的依赖关系,从而来捕捉输入句子的内部结构与交互。 自注意力机制正式介绍出自《Attention is all you need》,是Transformer和BERT的核心结构。  输出层: 和BiDAF相同,模型为每一个位置预测作为答案片段的开始与结束位置的概率分布。
p
1
=
s
o
f
t
m
a
x
(
W
1
[
M
0
;
M
1
]
)
p^1=softmax(W_1[M_0;M_1])
p1=softmax(W1[M0;M1])
p
2
=
s
o
f
t
m
a
x
(
W
2
[
M
0
;
M
2
]
)
p^2=softmax(W_2[M_0;M_2])
p2=softmax(W2[M0;M2]) 最终的损失函数:
L
(
θ
)
=
−
1
N
∑
i
N
[
l
o
g
(
p
y
i
1
1
)
+
l
o
g
(
p
y
i
2
2
)
]
L(\theta)=-\frac{1}{N}\sum_i^N[log(p^1_{y_i^1})+log(p^2_{y_i^2})]
L(θ)=−N1i∑N[log(pyi11)+log(pyi22)]
输出层: 和BiDAF相同,模型为每一个位置预测作为答案片段的开始与结束位置的概率分布。
p
1
=
s
o
f
t
m
a
x
(
W
1
[
M
0
;
M
1
]
)
p^1=softmax(W_1[M_0;M_1])
p1=softmax(W1[M0;M1])
p
2
=
s
o
f
t
m
a
x
(
W
2
[
M
0
;
M
2
]
)
p^2=softmax(W_2[M_0;M_2])
p2=softmax(W2[M0;M2]) 最终的损失函数:
L
(
θ
)
=
−
1
N
∑
i
N
[
l
o
g
(
p
y
i
1
1
)
+
l
o
g
(
p
y
i
2
2
)
]
L(\theta)=-\frac{1}{N}\sum_i^N[log(p^1_{y_i^1})+log(p^2_{y_i^2})]
L(θ)=−N1i∑N[log(pyi11)+log(pyi22)]【本文地址】